LLM의 출력 품질과 안전성을 극대화하기 위한 Negative Prompting의 이론적 배경, 작동 메커니즘, 4가지 핵심 유형 및 실전 최적화 가이드라인을 심층 분석합니다.
 LM과의 상호작용에서 긍정 지시만큼이나 Negative Constraint의 설계는 정밀한 제어를 위해 필수적입니다. 프롬프트 엔지니어링의 고도화된 기법인 Negative Prompting은 모델이 원치 않는 Anti-patterns로 수렴하는 것을 방지하는 강력한 가드레일 역할을 수행합니다.
LM과의 상호작용에서 긍정 지시만큼이나 Negative Constraint의 설계는 정밀한 제어를 위해 필수적입니다. 프롬프트 엔지니어링의 고도화된 기법인 Negative Prompting은 모델이 원치 않는 Anti-patterns로 수렴하는 것을 방지하는 강력한 가드레일 역할을 수행합니다.
본 가이드에서는 단순한 금지 명령을 넘어, 트랜스포머 아키텍처의 확률 분포 제어 원리와 실제 적용 사례의 단계별 비교를 통해 부정 지시가 출력 품질과 일관성에 미치는 효과를 구체적으로 살펴봅니다.
Negative Prompting의 정의와 작동 원리
Negative Prompting은 프롬프트 내에 'do not', 'avoid', 'never' 등의 부정 지시어를 삽입하여 특정 토큰의 생성 확률을 억제하는 전략입니다. 이 기법은 본래 이미지 생성 AI의 CFG(Classifier-Free Guidance) 메커니즘에서 유래하였으나, 현재는 텍스트 LLM의 Self-Attention 가중치 조절을 통한 정밀 제어 기법으로 확장되었습니다.
기술적 관점에서 LLM은 입력된 부정 지시어를 처리할 때 해당 의미론적 방향의 토큰 확률 분포를 낮추는 방식으로 작동합니다. 이는 모델의 Alignment Failure를 방지하는 데 매우 효과적입니다. 긍정 지시가 맥락에 따라 모호하게 해석될 수 있는 반면, 부정 지시는 독립적으로 검증 가능한 명확한 경계를 형성하여 출력의 결정론적 성격을 강화하는 특성을 가집니다.
긍정 지시만으로 해결되지 않는 문제점
LLM은 RLHF 과정을 거치며 '친절한 어시스턴트' 페르소나를 내재화하게 됩니다. 이러한 특성은 일반적인 대화형 인터페이스에서는 사용자 경험을 높이는 요소가 되지만, 엄격한 구조화 데이터 추출 환경에서는 심각한 노이즈로 작용합니다.
사용자 쿼리 반복 (Echoing)
모델이 답변을 시작하며 "제공해주신 참고문서에 따르면..." 또는 "질문하신 내용에 대해 답변드리겠습니다"와 같은 문구를 삽입하는 현상입니다. 이는 컨텍스트 윈도우 내의 중복 정보를 생성하여 연산 비용을 증가시키고 정보 밀도를 저하시키는 결과를 초래합니다. API 호출 기반의 서비스에서는 이러한 불필요한 출력 토큰이 곧 운영 비용의 상승으로 직결됩니다.
임의의 형식 적용 (Arbitrary Formatting)
모델이 자체적인 판단으로 불필요한 마크다운 문법을 삽입하는 경우입니다. 이는 정규표현식 기반의 데이터 추출이나 JSON 파서의 정상적인 작동을 방해하여 시스템의 견고성을 떨어뜨립니다.
불필요한 마무리 문구(Politeness Hallucination)
"도움이 되길 바랍니다", "추가 질문이 있으시면 언제든 말씀해 주세요"와 같은 마무리말은 텍스트 생성의 종결성을 흐트러뜨립니다. 후속 프로세스에서 텍스트를 결합하거나 가공해야 하는 자동화 환경에서 이러한 문구는 데이터 품질 저하의 주된 원인이 됩니다.
부정 프롬프팅의 4가지 핵심 유형
부정 프롬프팅은 배제하고자 하는 대상의 속성에 따라 네 가지 전략적 유형으로 분류되며, 각 유형은 모델의 서로 다른 레이어에 영향을 미칩니다.
1) 내용기반 부정 프롬프팅
특정 주제, 민감 정보, 혹은 편향된 시각을 차단하여 데이터 거버넌스를 준수하는 데 목적이 있습니다. 데이터 보안 및 신뢰성 확보를 위한 핵심 전략입니다.
- 예시: "Hallucination 방지를 위해 확인되지 않은 사실을 단정적으로 서술하지 마시오", "개인 식별 정보를 생성하지 마시오."
2) 형식 기반 부정 프롬프팅
출력의 구조적 무결성을 위해 특정 레이아웃이나 문법을 배제합니다. 이는 주로 다운스트림 태스크와의 호환성을 위한 제어 기법으로 활용됩니다.
- 예시: "Markdown 문법을 사용하지 마시오", "인사말을 앞에 붙이지 마시오."
3) 어투·스타일 기반 부정 프롬프팅
브랜드 톤앤매너 유지를 위해 특정 어휘나 수사적 표현을 억제합니다. 언어적 일관성 및 가독성 최적화를 위해 필수적입니다.
- 예시: "Superlatives(최고, 혁신적 등) 사용을 지양하시오", "전문용어를 설명 없이 사용하지 마시오."
4) 구조적 기반 부정 프롬프팅
모델의 추론 메커니즘이나 행동 패턴 자체를 제어하여 연산 효율성과 응답의 간결성을 확보합니다.
- 예시: "중간 추론 과정(CoT)은 출력하지 마시오", "사용자의 쿼리를 그대로 반복(Echoing)하지 마시오."
실전 도메인별 적용 사례
Negative Prompting은 다양한 산업 도메인에서 AI의 안전성과 운영 효율성을 제고하는 핵심 파라미터로 활용됩니다. 아래 표는 각 분야별 실전 적용 사례를 요약한 것입니다.
| 분야 | 주요 목적 | 핵심 부정 지시 예시 |
|---|---|---|
| 이미지 생성 AI | Artifact 제거 및 품질 최적화 | Blurry, Distortion, Low-quality, Noise exclusion |
| LLM 챗봇 | Out-of-scope 방지 및 일관성 | 범위 외 질문 답변 금지, 추측성 답변 지양 |
| 마케팅 콘텐츠 | Compliance 준수 및 브랜드 보호 | Unverified claims, Slang, 과장된 형용사 사용 금지 |
| 코드 생성 | Security 및 Maintainability 확보 | Magic numbers 사용 금지, Vulnerable functions 제외 |
비교 분석: 프롬프트 한 줄이 만드는 차이
Eureka Flow에서 동일한 인풋으로 시스템 프롬프트 조건만 달리했을 때 출력이 어떻게 달라지는지 3단계로 비교한 결과입니다.
1단계: 기본 실행
시스템 프롬프트에 역할(Role)만 부여하고 별도의 제약을 두지 않았을 때, 모델은 매우 높은 Verbosity를 보였습니다. 서론과 결론은 물론, 요청하지 않은 형식까지 포함되어 정보의 가독성은 높으나 데이터 처리 관점에서는 노이즈가 가장 많은 상태로 나타났습니다.

2단계: 긍정 지시만 적용 (Positive-Only)
"마크다운 Header를 사용하세요"라는 긍정 지시를 추가했습니다. 결과적으로 지정된 형식은 준수되었으나, 기존의 리스트는 유지되어 긍정 지시만으로는 원치 않는 패턴을 억제하는 데 한계가 있음을 보여줍니다.

3단계: Negative Prompting 적용
"사용자 쿼리를 반복하지 말 것(No Echoing)", "숫자 리스트를 사용하지 말 것" 등의 부정 지시를 명시했습니다. 그 결과, 모델은 불필요한 수식어 없이 핵심 정보가 담긴 Header와 Bullet 포인트만을 출력했습니다. 이는 부정 지시가 모델의 출력 범위를 효과적으로 제한하여 예측 가능성을 높임을 보여줍니다.
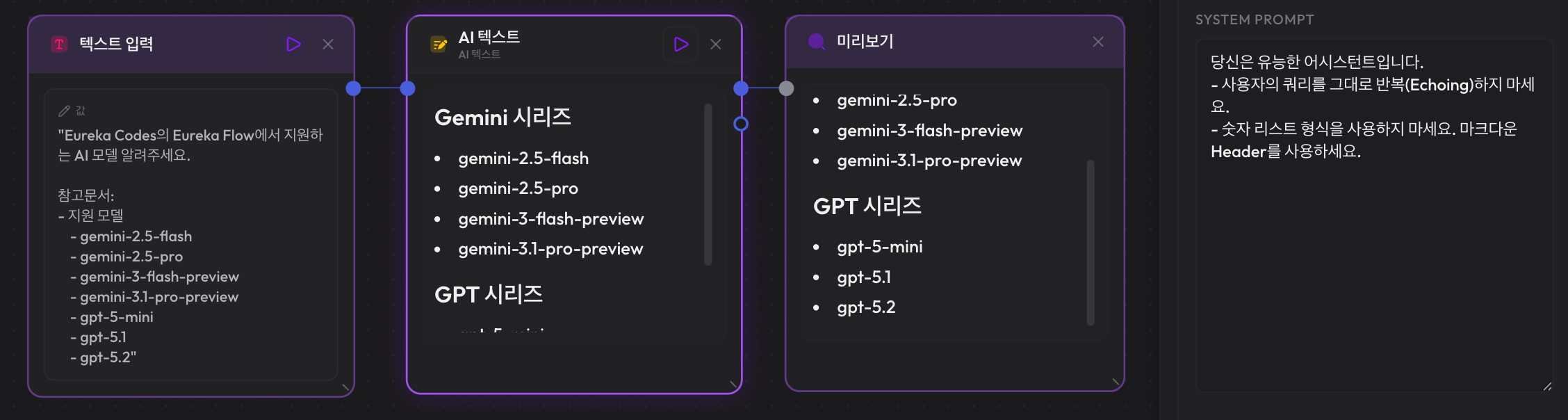
| 구분 | 긍정 지시만 적용 | Negative 적용 |
|---|---|---|
| 서론/마무리 | 포함 (제거 불가) | 완전 제거 |
| 숫자 리스트 | 임의 적용 | 완벽 제어 |
| 결과 예측성 | 낮음 | 매우 높음 |
시너지를 극대화하는 프롬프트 기법 결합
Negative Prompting은 단독 사용보다 고도화된 프롬프트 기법들과 결합될 때 모델의 확률적 변동성을 최소화할 수 있습니다.
- Chain-of-Thought 결합: 내부 추론은 정교하게 유도하되 "중간 과정은 출력하지 마시오"라고 지시함으로써 정확도와 간결성을 동시에 확보할 수 있습니다.
- Role-specific 결합: 페르소나를 부여하면서 "해당 역할의 경계를 넘는 행동"을 명시하여 역할의 선명도(Role Clarity)를 높입니다.
- Contrastive Few-Shot: Positive 예시와 Negative 예시를 동시에 제공하고 나쁜 패턴을 배제하도록 지시하여 모델의 패턴 인식 능력을 극대화합니다.
- JSON Prompting 결합: 구조화된 데이터 요청 시 "JSON 외 텍스트 포함 금지" 지시는 파싱 에러를 획기적으로 낮추는 필수 전략입니다.
성공적인 Negative Prompting을 위한 가이드라인
효과적인 부정 프롬프팅을 위해 반드시 준수해야 할 4대 엔지니어링 원칙을 제시합니다.
- 구체성 원칙(Specificity): 모호한 금지 대신 열거형 제약을 사용하여 모델의 해석 범위를 좁혀야 합니다. "나쁜 표현 금지"보다는 구체적인 금지어 리스트를 제공하는 것이 효과적입니다.
- 우선순위 배치 원칙(Prefix Priority): LLM은 프롬프트 상단의 지시를 더 강하게 반영하는 경향이 있습니다. 따라서 핵심적인 제약 사항은 프롬프트 전면에 배치하십시오.
- 균형 원칙(Balance): 부정 지시의 비중을 전체의 30% 이하로 유지해야 합니다. 과도한 제약은 '역설적 강화(Ironic Rebound Effect)'를 유발하여 오히려 금지된 주제에 모델이 집착하게 만들 수 있습니다.
- 반복 최적화 원칙(Iterative Optimization): 모델 버전 업데이트에 따른 반응 차이를 고려하여 지속적인 A/B 테스트를 수행하고 지시문을 정교화해야 합니다.
Negative Prompting에 대해 자주 묻는 질문
Q: 부정 프롬프트를 사용하면 모델이 100% 지시를 준수하나요? A: LLM은 확률적 모델이므로 완벽한 준수를 보장할 수 없습니다. 따라서 서비스에 따라 출력 후처리 필터를 병행하는 것이 안전합니다.
Q: 부정 지시가 모델의 추론 성능(Reasoning)을 저하시킬 가능성이 있습니까? A: 과도하고 복잡한 제약은 모델의 창의적 사고를 일부 제한할 수 있습니다. 그러나 형식 제어(Format Control)를 목적으로 하는 Negative Prompting은 오히려 불필요한 연산을 줄여 핵심 정보에 대한 집중도를 높이므로, 결과의 정확도를 향상시키는 긍정적인 효과를 제공합니다.
Q: 부정 지시가 과도할 경우 발생하는 부작용은 무엇인가요? A: '역설적 강화' 현상으로 인해 오히려 금지된 주제에 모델이 집착하거나, 응답의 정보 밀도가 지나치게 낮아지는 '소극적 응답' 문제가 발생할 수 있습니다.
Q: 'Avoid'와 같은 완곡한 표현보다 'Do not'과 같은 강한 부정이 효과적인가요? A: LLM의 Attention 메커니즘은 명확하고 단호한 금지 명령(Negative Constraint)에 더 민감하게 반응합니다. 따라서 "가급적 피해주시기 바랍니다"라는 표현보다는 "하지 마십시오(Do not)", "금지(Forbidden)"와 같은 명확한 표현을 사용하는 것이 제어 효율성 측면에서 권장됩니다.
Q: 토큰 비용 및 레이턴시에 영향이 있나요? A: 네, 긴 금지 목록은 컨텍스트 윈도우를 점유하여 비용을 높이고 연산 부하를 증가시킵니다. 핵심적인 제약 위주로 최적화하여 작성하는 것이 경제적입니다.
Negative Prompting은 단순히 출력을 줄이는 기술이 아니라, AI 파이프라인의 신뢰성을 결정짓는 전략적 도구입니다. 긍정 지시만으로 해결되지 않던 노이즈를 직접 명시하는 것만으로 출력의 일관성이 달라지고, 그 일관성이 곧 운영 비용과 시스템 안정성으로 이어집니다.
적절한 부정 지시 하나가 파싱 에러를 줄이고, 후처리 로직을 단순화하며, 자동화 파이프라인 전체의 품질을 끌어올립니다. 모델을 제어하는 데 쏟던 시간을 줄이고, 본래의 서비스 설계에 집중할 수 있게 됩니다.
원하지 않는 패턴이 사라지는 순간, 경험해 보고 싶지 않으신가요? Eureka Flow로 직접 테스트해 보세요.